

7 pasos para predecir una fuga de clientes con KNIME
La importancia de retener a tus clientes

Hoy sabemos que conseguir un cliente nuevo es entre 6 y 7 veces más caro que mantenerlo. Por este motivo, una de las principales tareas en la gestión de una cartera de clientes es su retención.
La importancia de retener a tus clientes
El análisis de datos indica que los sectores en los que más incidencia tiene la tasa de abandono son Telecomunicaciones, Prensa y Energía. Esto es debido principalmente a modelos de negocio basados en contratos temporales o de subscripción. Además, se estima que el 68% de los clientes que cambian de empresa es porqué han recibido una atención deficiente.
En la actualidad, gracias a los avances en computación y el registro constante de miles de transacciones, la contención de clientes es mucho más eficiente. De hecho, algunas investigaciones indican que un aumento de las tasas de retención de clientes de apenas un 5% incrementa las ganancias entre un 25% y un 95%, y que las empresas en crecimiento priorizan el éxito del cliente más que aquellas que se encuentran estancadas.Debemos, en definitiva, utilizar la información que nos dan para reducir la tasa de abandono, conocida como churn, identificándola primero, agrupando los clientes abandonistas según el perfil y entiendo las causas de este desapego para poder establecer unos protocolos de actuación y evitar, así, perder al cliente.
Entonces, ¿cómo retenemos a nuestros clientes?
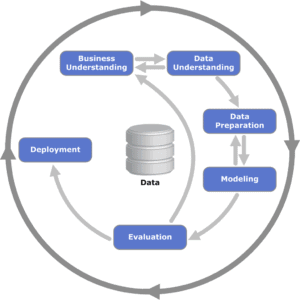
La respuesta es mediante algoritmos predictivos de fuga de clientes. Para ello, trabajamos con la metodología CRISP-DM (Cross-Industry Standard Process for Data Mining) que mediante un proceso jerárquico formado por varias tareas, ofrece a tu organización la estructura necesaria para obtener mejores y más rápidos resultados en la minería de datos.
- Comprensión del negocio
- Comprensión de los datos
- Preparación de los datos
- Modelado
- Evaluación
- Implantación o despliegue
- Visualización
Para realizar todo este proceso, utilizamos la herramienta KNIME que ofrece el ciclo completo de Data Mining. Con la posibilidad de conectarse a múltiples y heterogéneas fuentes de datos podremos unificar datos provenientes de distintas BBDD, archivos y servicios web diversos como Azure, etc. con muy poco esfuerzo.
Con una gran variedad de nodos para el preprocesamiento la herramienta ofrece las condiciones óptimas para la generación de procesos de ETL automatizada. Finalmente ofrece los principales algoritmos y métodos de evaluación para la generación de modelos potentes. Adicionalmente dispone de múltiples extensiones (Text Processing, Big Data con Spark y Hadoop, Deep Learning con TensorFlow y Keras y muchas más) que empoderan la herramienta aún más.
En definitiva, mediante KNIME podemos realizar todos los procesos divididos en los siete puntos que nos marca la metodología CRISP-DM que veremos a continuación a través de un proyecto real:
Comprensión del negocio
El cometido general de esta fase es entender los objetivos y requerimientos del proyecto desde una perspectiva de negocio y convertir este conocimiento en la definición de un problema de minería de datos y un plan preliminar para alcanzar los objetivos.
Partimos de una compañía del Sector de las Telecomunicaciones. Con una tipología de contrato para sus clientes que no exige permanencia. Por otro lado, la fluctuación de clientes es muy fuerte, con muchas entradas y salidas todos los meses. El objetivo de este proyecto es la retención de clientes mediante algoritmos predictivos de fuga de clientes.
Comprensión de los datos
En esta fase el objetivo principal es poder hacer una captura inicial de los datos a analizar para familiarizarse con ellos, identificar problemas de calidad en los mismos, detectar subconjuntos de los datos que pudieran ser interesantes para formular hipótesis específicas que validar posteriormente con el análisis, e incluso identificar las primeras claves del conocimiento que se puede extraer de los datos.
Para este caso, los datos disponibles son los siguientes:
- Datos personales con fuga marcada (Sistema ERP)
- Datos de contratación (Sistema ERP)
- Datos de uso (Sistema Monitorización de uso)
- Datos de facturación (Sistema Facturación)
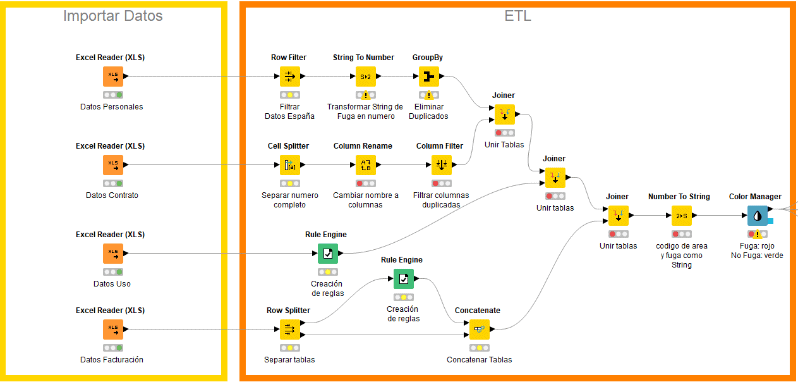
Preparación de los datos
Una vez seleccionados los datos, se pasa a la fase de la preparación de datos. La preparación de datos, a menudo llamada «preprocesamiento», es la etapa en la que los datos en bruto se limpian y organizan para la siguiente fase del procesamiento. Durante la preparación, los datos en bruto se verifican para detectar errores. El objetivo de este paso es eliminar los datos erróneos (datos redundantes, incompletos o incorrectos) y empezar a crear datos de calidad.
Para la preparación, KNIME permite la integración de múltiples fuentes de datos (BBDD SQL, Excel, CSV, Webservices/APIs)
- Datos Sistemas ERP, Monitorización, Facturación
Además, cuenta con gran cantidad de funciones para transformar los datos:
- Filtrar por país, agrupar por cliente, eliminar duplicados, cálculos y campos adicionales, etc.
Para facilitarnos el trabajo cuenta con workflows visuales e intuitivos:
- Drag&Drop de funciones, Conexiones visibles, etc.
Modelado
El modelado de datos es una manera de estructurar y organizar los datos para que se puedan utilizar fácilmente por las bases de datos. Se utiliza habitualmente en combinación con un sistema de gestión de base de datos. Los datos que se han modelado y preparado para este sistema se pueden identificar de varias maneras, como de acuerdo a lo que representan, o cómo se relacionan con otros datos.En KNIME disponemos de una amplia biblioteca de analítica avanzada:
- Algoritmos de clasificación (Fuga Si/No) para la predicción de la fuga de los clientes
Evaluación
Este paso evalúa el grado al que el modelo responde a los objetivos de negocio, y determina si hay alguna decisión de negocio que el modelo no cubra. Otra opción de evaluación es probar el modelo sobre escenarios de prueba. La evaluación también verifica otros resultados generados por la minería de datos.
El objetivo es resumir los resultados de evaluación en términos de criterios de éxito de negocio, incluyendo una declaración final estableciendo si el proyecto ha alcanzado los objetivos iniciales de negocio.
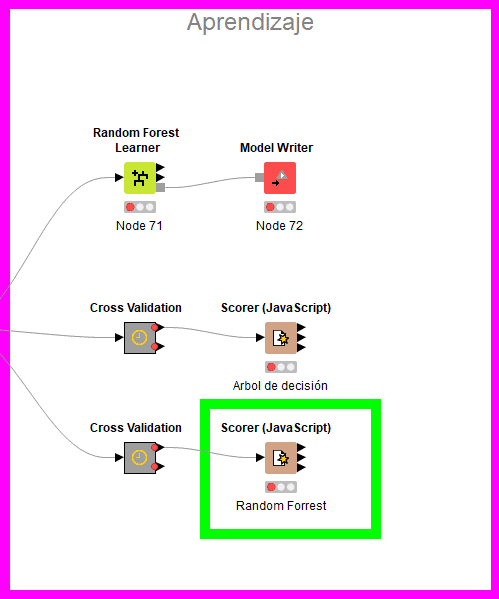
Evaluación y comparación de algoritmos a través de cross validation:
- Entrenamos el Random Forest y Árbol de decisión con 80% de los datos y los aplicamos al 20% restante verificando los resultados.
Elección de algoritmo y exportación del modelo entrenado
- Es Random Forest con un 93% de acierto el que tiene una fiabilidad más alta por lo que seleccionamos este.
Despliegue
La creación del modelo y su evaluación positiva no significa el final del proyecto. Se debe organizar el conocimiento adquirido gracias al proceso de minería de datos y presentarlo de una manera que sea utilizable en el contexto de negocio. Esto implica la integración de los modelos dentro de los procesos de toma de decisiones de la organización, además de requerir la implicación del cliente en los propios pasos de puesta en operación del modelo.
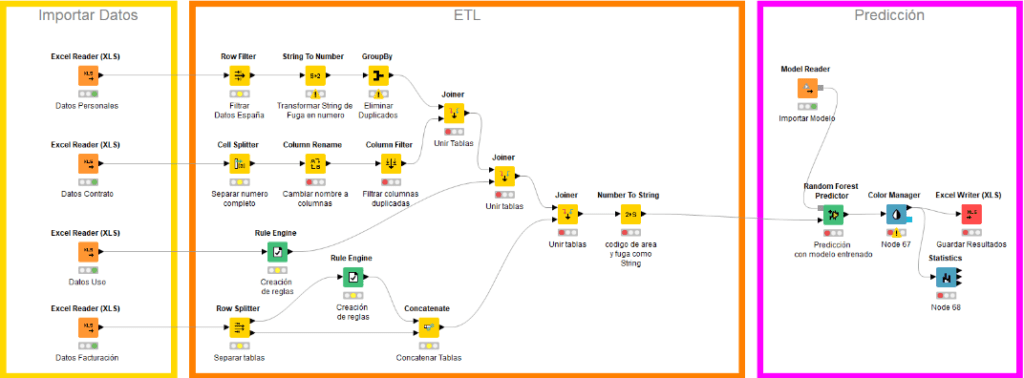
Workflow para la predicción:
- El workflow se conecta a las fuentes de datos y extrae los datos más nuevos para predecir a futuro los clientes que van a finalizar su contrato
Automatización del workflow:
- Con KNIME Server puedes automatizar tu workflow pudiéndose ejecutar hasta varias veces al día sin acción humana.
Integración de los resultados en el proceso:
- El equipo responsable de la retención de clientes recibe los resultados y dirige acciones de retención hacia los clientes con una probabilidad alta de fuga
Reducción de fuga de clientes de hasta un 30%
Visualización – Business Intelligence
Los resultados pueden ser integrados en un cuadro de mando de Business Intelligence intuitivo. De esta manera el equipo de retención de clientes puede analizar en detalle la situación y derivar una estrategia potente para evitar la fuga de los clientes.
 Contactar
Contactar