

Big Data: paralelización de datos con Apache Spark
Apache Spark es un software que se encarga de distribuir o paralelizar los datos a la hora de analizarlos.
Hoy en día se habla mucho de la paralelización de los datos en diferentes máquinas para procesar la información más rápido, ¿pero realmente que es eso? Paralelizar los datos en diferentes máquinas no es más que dividir los datos en archivos más pequeños. Estos archivos más pequeños son enviados cada uno a una máquina diferente. De esta forma, cada máquina procesará una pequeña parte del fichero inicial en lugar de analizar el fichero completo.

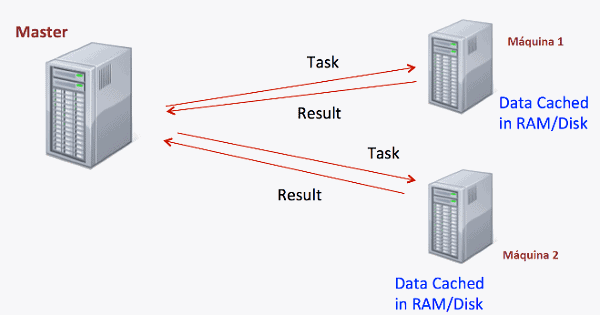
Si tenemos el siguiente archivo: consumos.csv con 2 columnas, la primera indica la hora a la que se recogieron los datos y la segunda indica el consumo de KW/h. Este fichero tiene 10 momentos diferentes en las que se han recogido los datos. Creamos un clúster con Spark como vemos en la siguiente figura:

Una de las máquinas es la encargada de controlar las operaciones, que recibe el nombre de máster, y las otras dos máquinas comunicadas con el máster, reciben el nombre de trabajadores. Si mandamos hallar la suma de KW/h a nuestro clúster, que procede de la siguiente forma:
- Divide el fichero consumos.csv en 2 ficheros, particion1.csv y particion2.csv, cada uno de ellos de 5 filas
- Manda a una máquina del clúster el fichero particion1.csv y a la otra el fichero particion2.csv
- Cada máquina del clúster hace la suma de la segunda columna y devuelve el resultado al master
- Una vez que el master ha recibido los resultados de cada máquina, suma las dos cantidades recibidas
- Spark devuelve la suma total de la columna de los consumos.
Ahora bien, si queremos hallar la media del consumo, cada máquina devuelve la suma como ha hecho antes y, también, devuelve el número de filas que tenía el fichero que ha analizado. En nuestro ejemplo, se actuaría de la siguiente forma:
- La máquina que procesa el fichero particion1.csv devolvería una suma de consumos de 0.981 y el número de filas que ha analizado: 5
- La máquina que procesa el fichero particion2.csv devolvería una suma de consumos de 0.864 y el número de filas que ha analizado: 5.
- La máquina master, suma el número de filas que envía cada máquina y suma cada una de las sumas que recibe de cada una de las máquinas y hace la siguiente división:

Veamos de manera gráfica cómo calcularía la media de los consumos:

Concluimos por lo tanto la simplicidad y velocidad que nos aporta Spark ante un problema de grandes dimensiones. Divide y vencerás!
 Contactar
Contactar