

Diseñando una arquitectura Big Data para procesamiento de datos de producción
La arquitectura perfecta para Big Data

Uno de los más grandes avances que ha tenido lugar en la última década ha sido la creación de herramientas capaces de procesar grandes cantidades de datos. En los inicios de la década de los 2000, Google comenzó a investigar métodos para procesar y almacenar datos de forma distribuida, dando lugar a un sistema de archivos distribuido (GFS) y un método de procesamiento llamado MapReduce.
A partir de allí, y gracias a la innovación de múltiples compañías que donaron sus metodologías y repositorios de código a la comunidad, fueron desarrollándose las herramientas que hoy nos permiten procesar enormes y multiples fuentes de datos: “Big Data”.
Cuando hablamos de Big Data nos referimos a datos masivos que pueden generarse a partir de dispositivos o acciones individuales de usuarios que, al ser relacionadas entre sí, dan información relevante del comportamiento de sistemas complejos.
Con la llegada de los dispositivos IoT, internet de las cosas, es posible recuperar datos de prácticamente cualquier máquina. En el campo logístico y productivo, es posible analizar datos de las máquinas que llevan a cabo las tareas industriales para determinar su eficiencia, cuando están fallando u optimizar su funcionamiento.
Un diseño eficiente de una arquitectura de Big Data en un entorno productivo sería capaz de realizar las siguientes funciones:
- Procesamiento de datos en tiempo real para determinar la eficiencia de procesos industriales
- Mezcla de datos generados por procesos por lotes (por ejemplo, datos de un ERP o CRM) con datos generados en tiempo real para realizar análisis financieros
- Generación de cuadros de mando que se actualicen a medida que los datos van siendo generado y procesados
- Análisis de incidencias que permitan generar planes de mantenimiento predictivo a partir de datos generados por dispositivos IoT
- Optimización de procesos, como, por ejemplo, optimización de rutas o reasignación de recursos con tiempos de respuesta casi inmediatos
- Análisis de tendencias y generación de recomendaciones a partir de la operativa habitual
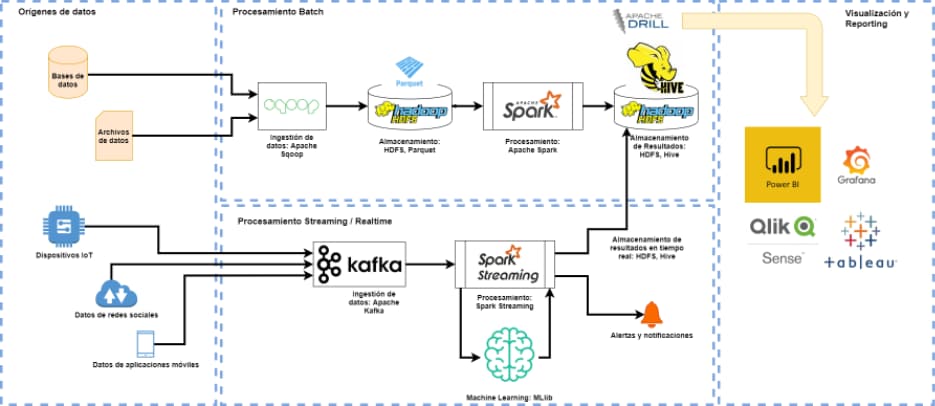
La arquitectura perfecta para Big Data
No existe una arquitectura perfecta y estándar. Cada proyecto, cada caso en particular, condicionará las características de la arquitectura ideal. Para llegar a esa arquitectura ideal es necesario evaluar cuales y cuantos dispositivos pueden ofrecer estos datos o pueden convertirse en inteligentes a través de sensores capaces de recopilar los datos requeridos para el análisis. A partir de estos datos, dependiendo de la frecuencia de generación del dato y las correlaciones necesarias con otros procesos como bases de datos con información empresarial, se crea una arquitectura tecnológica que utilizando las herramientas de procesamiento de Big Data, puede ser capaz de generar la información relevante para la toma de decisiones de negocios, mejorando la eficiencia de los procesos productivos y anticipándose a posibles incidencias que puedan disminuir la capacidad de producción.
En LIS-Solutions trabajamos con tecnologías punteras de procesamiento de datos tales como Kafka y Spark de la suite Apache Hadoop, así como tecnologías de visualización en cuadros de mando como Qlik Sense, Power BI y Grafana. Estas tecnologías nos han permitido realizar sistemas de procesamiento de datos capaces de ofrecer a nuestros clientes información relevante sobre sus procesos productivos que les han permitido analizar y optimizar el funcionamiento de su negocio.
 Contactar
Contactar